개요
- Object Detection = Localization + Classification. (locatlization은 회귀문제, classification은 분류문제)
- one stage detector: localization과 classification을 하나의 네트워크에서 처리
- 속도가 빠름. 정확도가 낮음.
- Two stage detector: localization과 classification을 나눠서 순차적으로 실행 처리
- 속도가 떨어짐. 정확도가 높음.
- 실제 사용 시, 실시간 검출을 해야하는 경우가 많아지며 속도가 빠른 것이 중요해짐. ⇒ one stage detector를 사용해 정확도를 높이는 방법 연구.
- one stage detector: localization과 classification을 하나의 네트워크에서 처리
출력값
- Bounding Box의 위치는 4개 값으로 구성되어 있음. (센터의 x, y, w, b).
- BBox는 class 명까지 포함한 것.
- 좌상단이 x, y 좌표의 min, 우하단이 x, y 좌표의 max.
- 좌표와 크기를 이미지의 width와 height 대비 비율로 지정한다. ⇒ 원본 이미지가 resize 되어도 곱해버리기만 하면 되기때문에 영향을 받지 않음.
- Confidence score
- Bonding Box 안의 object가 내가 찾는 대상 중 하나일 확률 (값: 0.0~1.0)
- 고양이/개 분류 할때, BBox 내에 둘 중 하나일 확률임. 즉 0.9여도, 개를 찾는 것인데 고양이일 수도 있음.
- object detection시 무조건 N 개의 object를 bounding box로 찾아야 함. 찾고자 하는 object에 대해 confidence score가 높게 나올 것. ⇒ 후처리를 통해 낮은 것은 제거하고, 높은 것을 결과 값으로 추론.
- Bonding Box 안의 object가 내가 찾는 대상 중 하나일 확률 (값: 0.0~1.0)
Object Detection 성능 평가
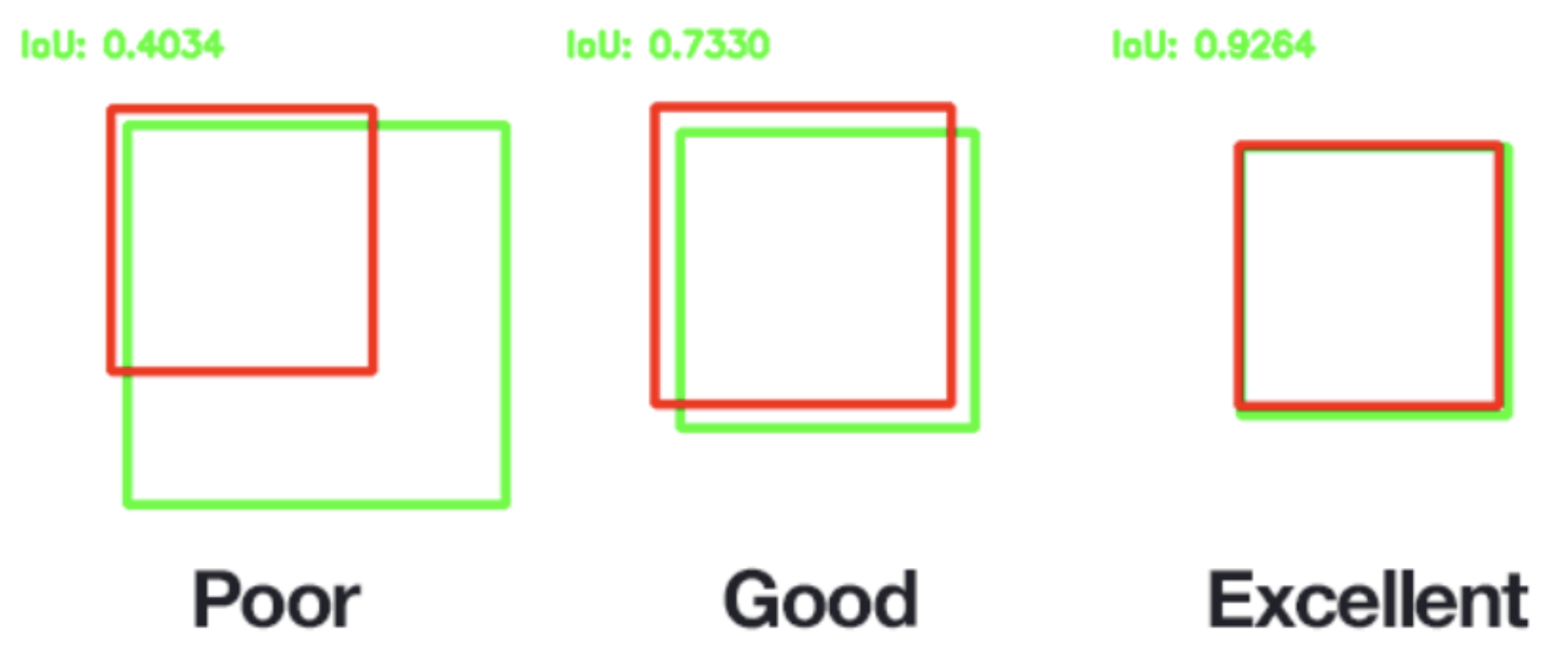
- IoU (Intersection Over Union)
- 모델이 예상한 BBox와 정답 BBox 간의 겹치는 면적을 나타내는 평가지표.
- 수식 : 두 영역의 교집합 영역 / 두 영역의 합집합 영역
- 임계값(IoU Threshold): 겹치는 정도를 판단하는 값.
- 정할 수 있으며, 보통 0.5 이상이면 많이 겹치는 것으로 판단.
- 임계값을 높이면 재현율은 떨어지고 정밀도는 올라감
- 임계값을 낮추면 재현율은 올라가고 정밀도는 떨어짐.
- mAP(mean Average Precision)
- 재현율(Recall)의 변화에 따른 정밀도(Precision) 값을 평균화
- 정밀도 = TP / 모든 예측
- 재현율 = positive로 맞춘 것/ positive 예측
- 정밀도랑 재현율 모두 높아야함.
- 정밀도가 0.5이고 재현율이 1.0이면 찾는 경우가 반반이지만, 찾으면 100퍼 맞는다는 것. (아래 그림 해석)

Confusion Matrix 와 Object Detection
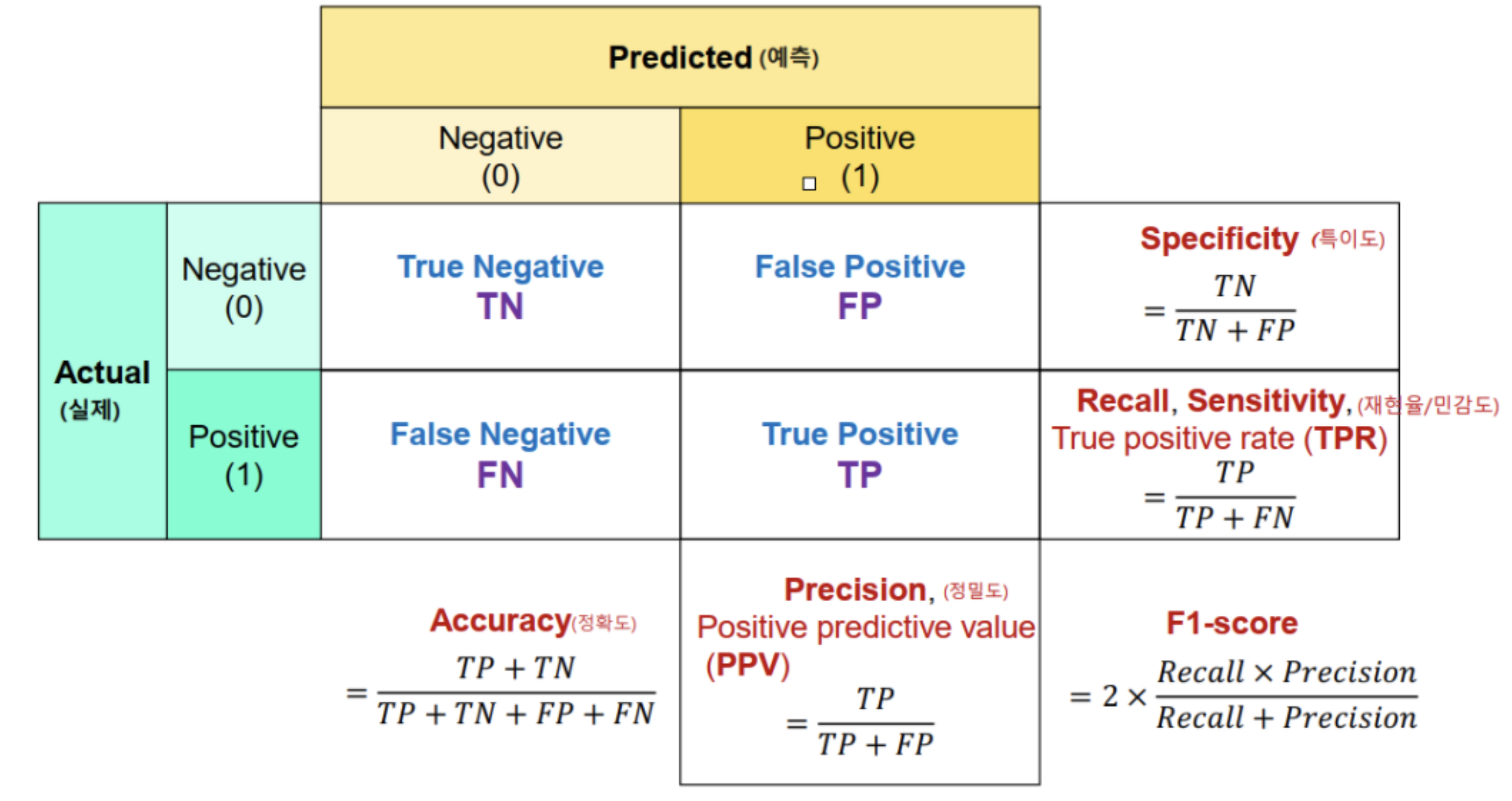
- confusion matrix 계산 하려면 scikit-learn 이용하면 됨.
import numpy as np
from sklearn.metrics import confusion_matrix
## class: 0,1 (이진분류)
y = np.array([0, 1, 1, 1, 0])
pred = np.array([0, 0, 1, 1, 1])
confusion_matrix(y, pred)- 정확도, 재현율, 정밀도 함수
from sklearn.metrics import accuracy_score, recall_score, precision_score
Object Detection에서의 TP, FP, FN
- FP
- 다른 class로 예측한 경우
- IoU가 threshold 이하인 경우
- 아예 잘못된 위치로 예측한 경우
- FN
- 아예 찾지 못한 경우
- Precision-Recall curve
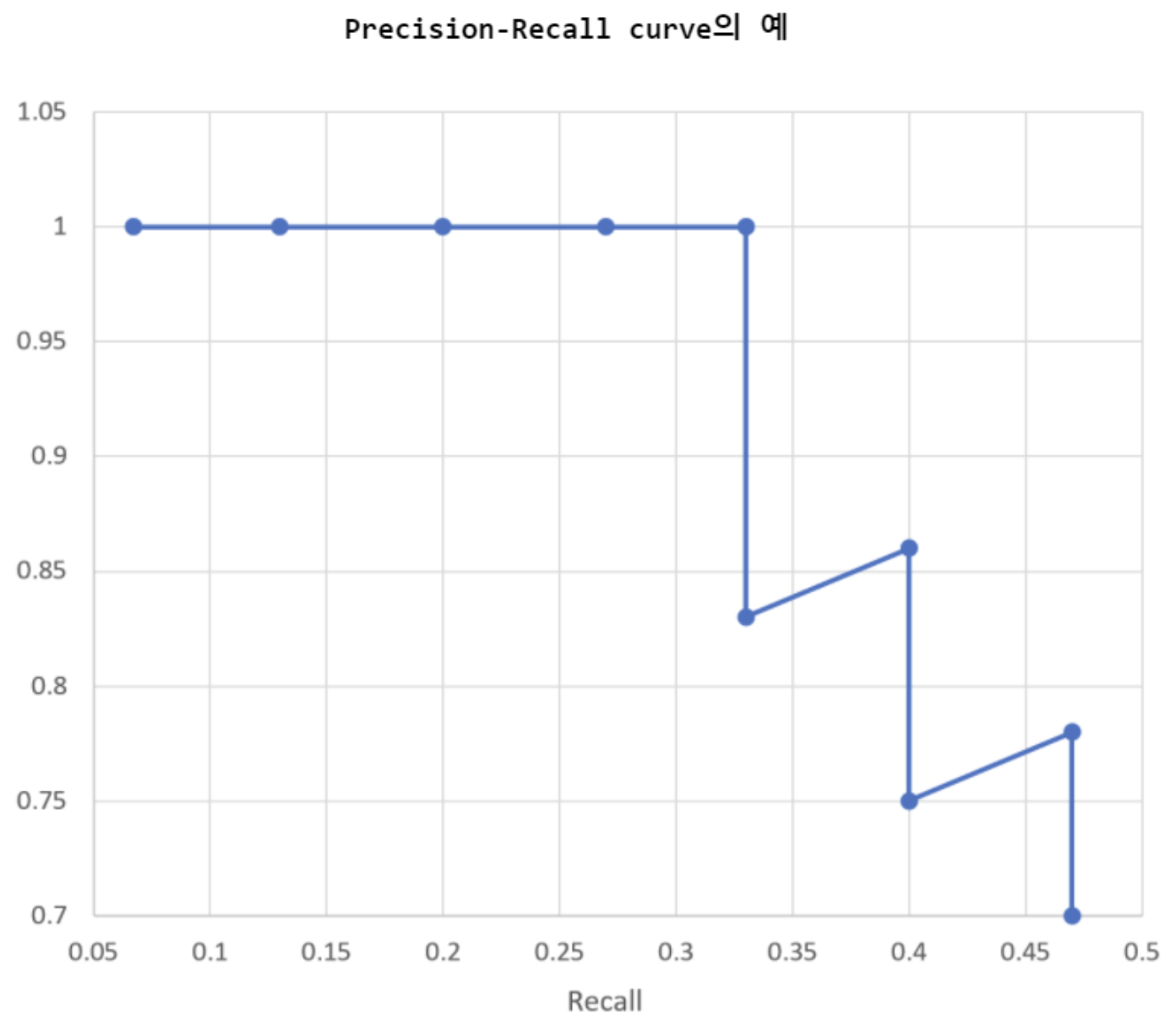
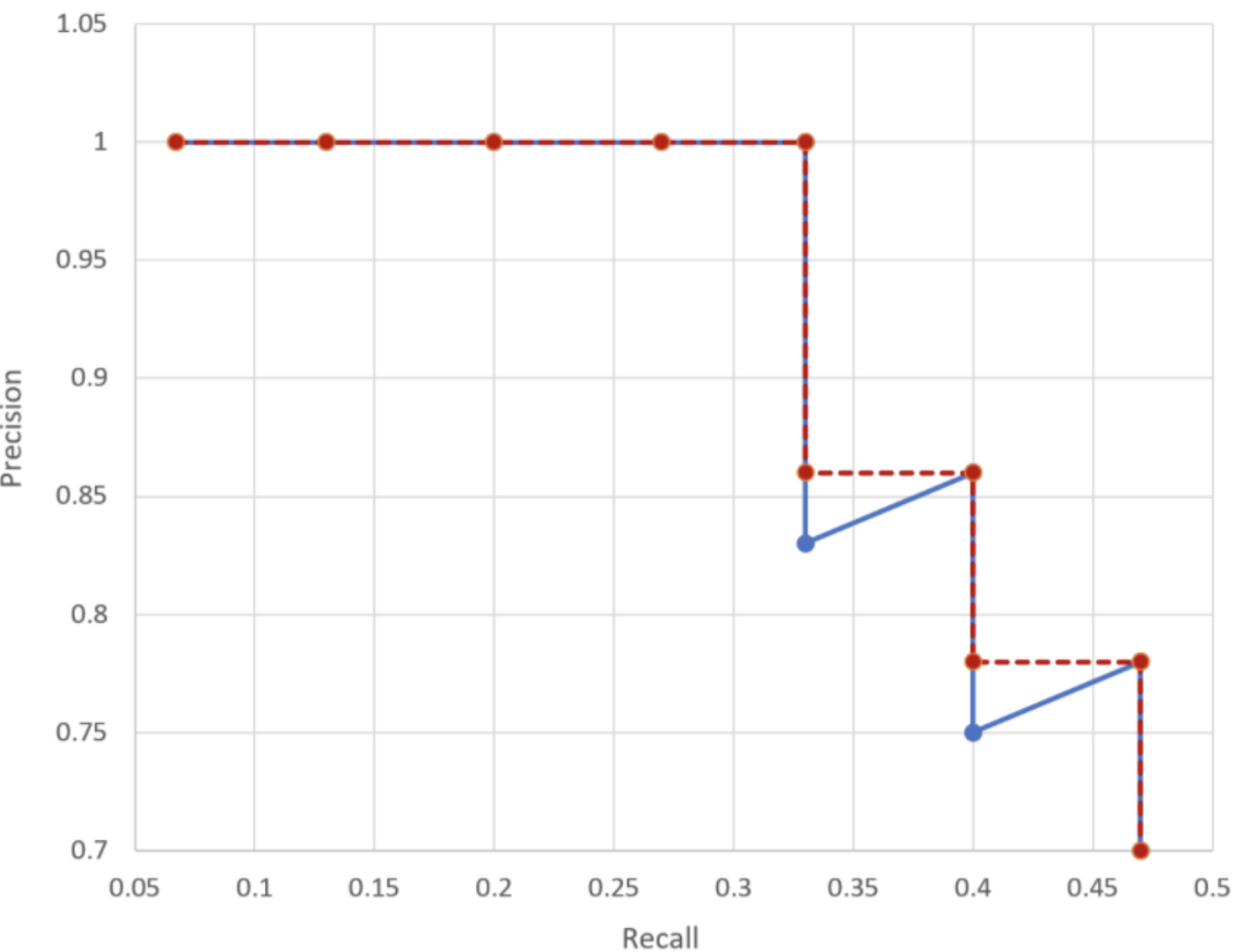
- Average Precision
- 선 아래 면적 계산. 이 면적이 1이랑 가까울 수록 좋은 성능.
Model 추론 결과 후처리
- NMS(Non Max Suppression)
- Bounding Box들 중에서 비슷한 위치에 있는 겹치는bbox들을 제거하고 가장 적합한 bbox를 선택하는 방법
- Soft NMS
- 물체가 겹쳐져있을 경우 하나밖에 찾지 못해 mAP가 낮아짐. 이를 해결하는 방식.
- 겹치는 bbox의 경우 confidence score가 낮은 것을 제거하지 않고 confidence score를 줄여서 남긴다.
Uploaded by N2T